
Hire Senior LLM Developers.
Engineers who build production LLM features — chat, agents, RAG, structured generation — backed by real evals.
80+
Products shipped
8+ yrs
In production
5–10 days
Time to start
24h
Reply time
Overview
LLM development in 2026 has separated into two cohorts: people who can run a chat completion, and people who can ship a reliable LLM feature into production. Our LLM developers are the second. They've shipped RAG systems with measurable retrieval quality, AI agents with safety boundaries that hold under adversarial input, and structured-output features that fail predictably when the model is wrong. We build with the AI SDK, prompt caching, and provider-agnostic patterns. Cost discipline, latency budgets, and evaluation harnesses are part of every project.
Why Techyor.
Senior. Specialist. Shipping.
Production AI, not demo AI
Our LLM features ship with retries, fallbacks, evals, observability, and cost monitoring. They behave when the model is slow, wrong, or unavailable.
Provider-agnostic
Vercel AI Gateway or Portkey-style abstractions — switch from Claude to GPT to Gemini in config, not in code. Vendor lock-in is a choice, not a default.
Evaluation-driven
Every LLM feature ships with a test set, automated scoring, and regression alerts. We can prove the feature improved, not just hope it did.
What they cover.
Skills and stack.
Capabilities
- Claude (Opus, Sonnet, Haiku) — including prompt caching, tool use, extended thinking
- OpenAI GPT-5 family, Gemini, open-weight models (Llama, Mistral)
- Vercel AI SDK, AI Gateway, MCP servers
- RAG — chunking strategies, embedding models, hybrid search, reranking
- Agent frameworks — LangGraph, CrewAI, custom orchestration
- Structured generation — schema-constrained output, retry-on-validation-fail
- Evaluation — Promptfoo, LangSmith, custom LLM-as-judge harnesses
- Observability — token usage, latency, cost tracking per feature
- Cost optimization — prompt caching, model routing, response caching
Tech stack
The people behind the work.
Hire them directly.


Selected work.
LLM Developers in the wild.
A small slice of 5 projects where this role led the work.
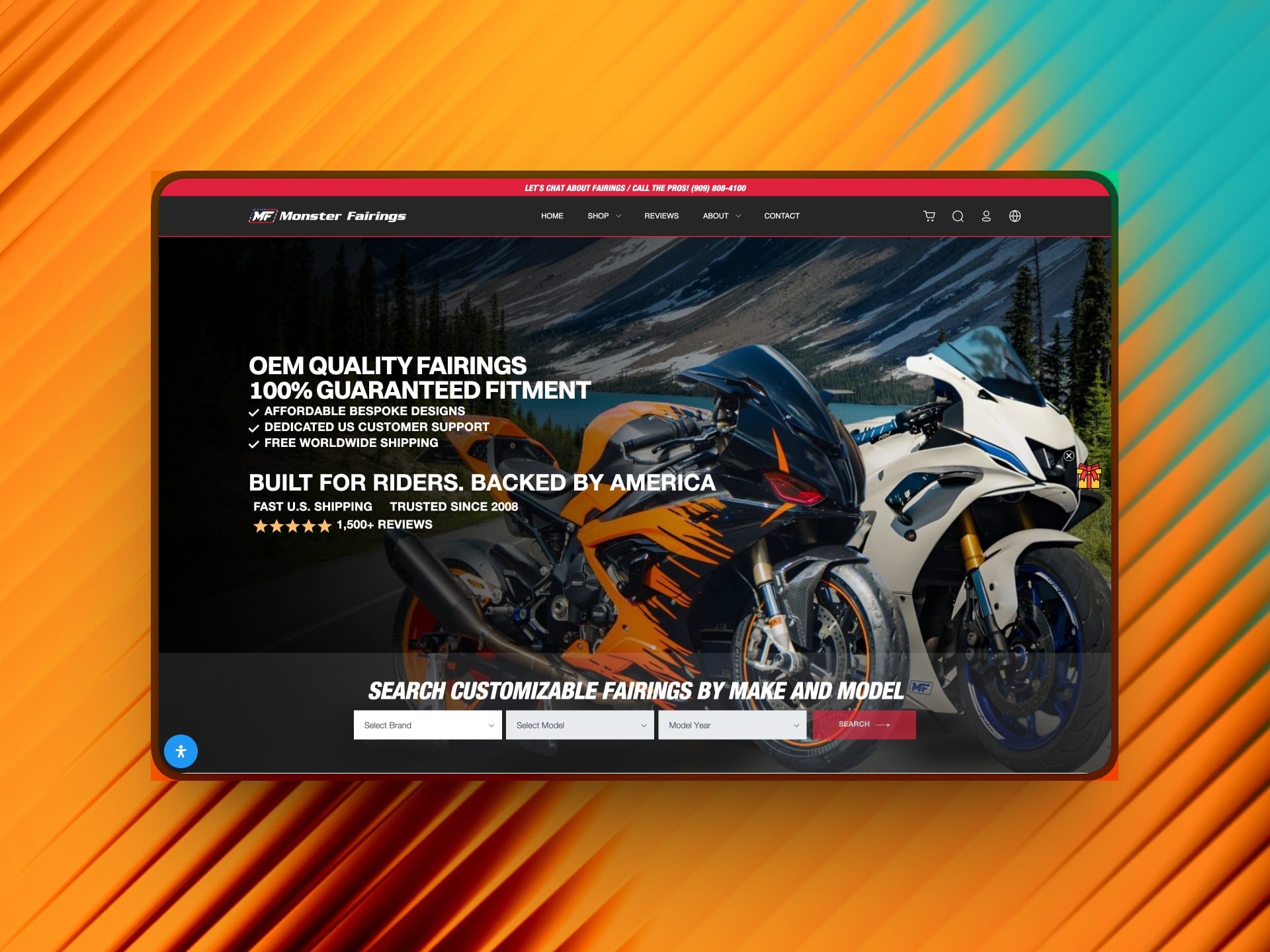
Monster Fairings
A global e-commerce platform with AI-powered visualization, managing 5000+ fairings and serving riders across seven countries.
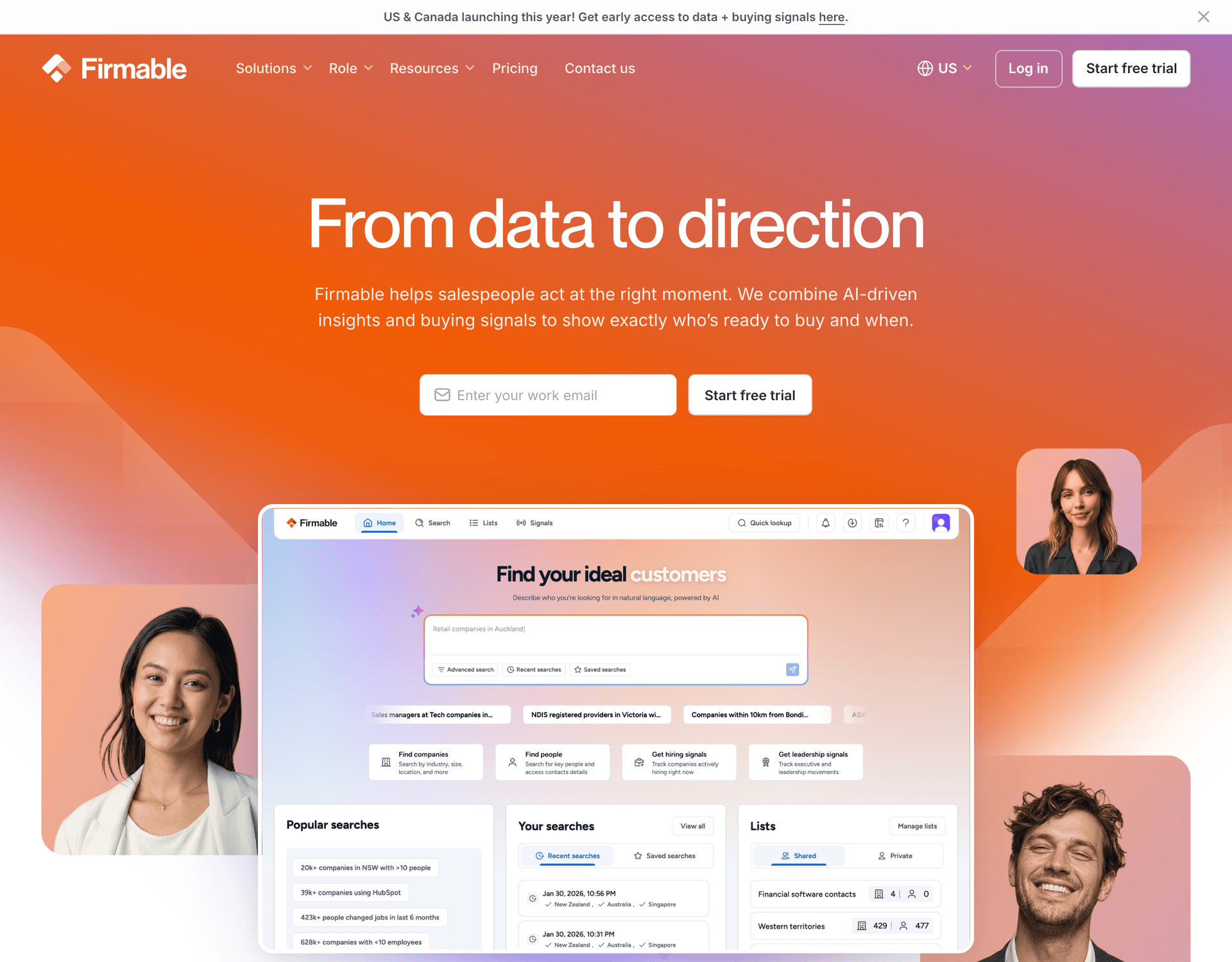
Firmable
AI-driven B2B Sales Intelligence platform providing buying signals and sales insights
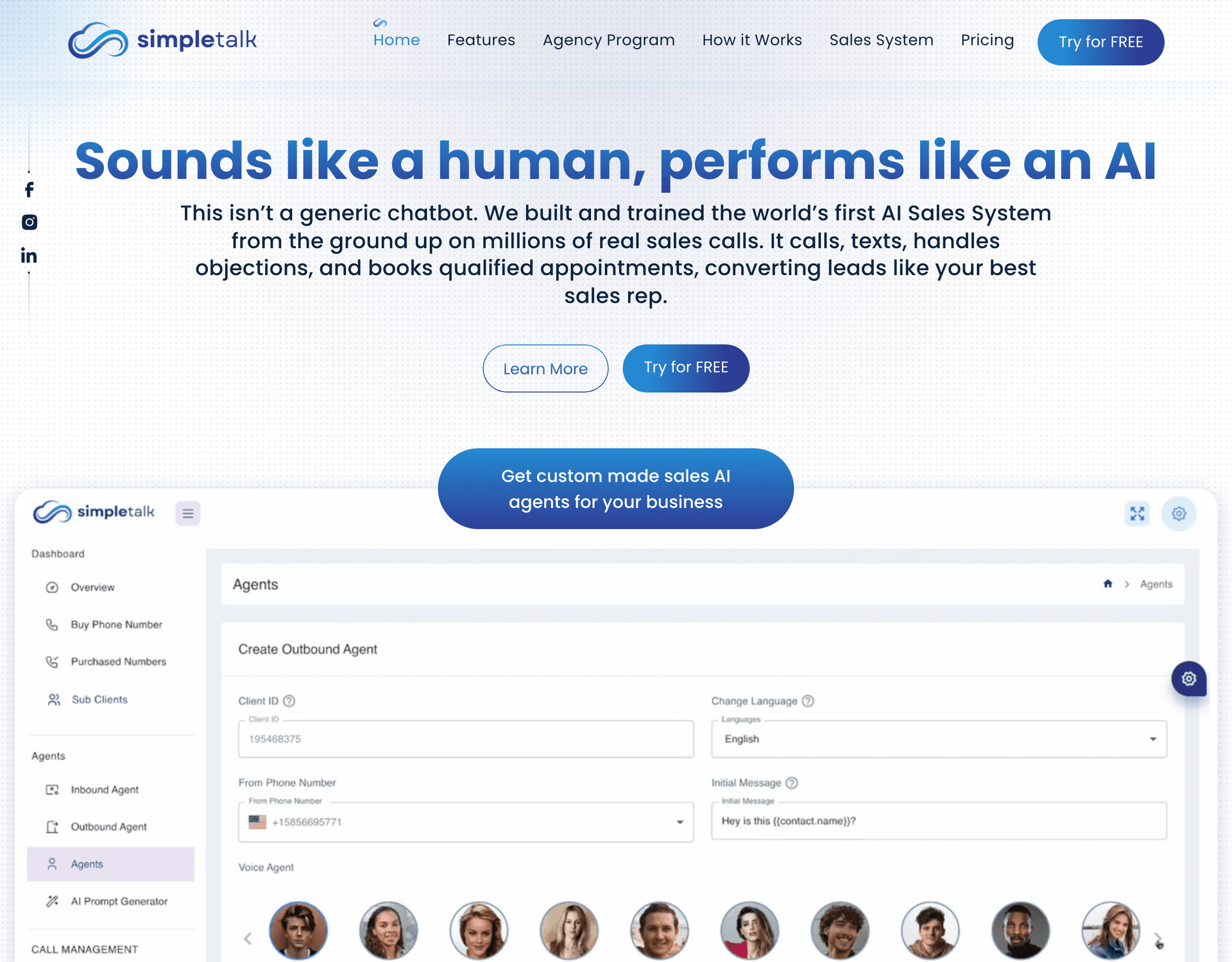
SimpleTalk AI
Enterprise AI voice sales platform handling 147K+ calls across 12 languages, with multi-channel agents, white-label tenancy, and deep CRM integrations.

ConvertBankStatement
A specialized PDF-to-Excel conversion platform powered by a custom Python OCR engine, supporting 250+ bank formats and 30+ currencies for accountants and finance teams worldwide.
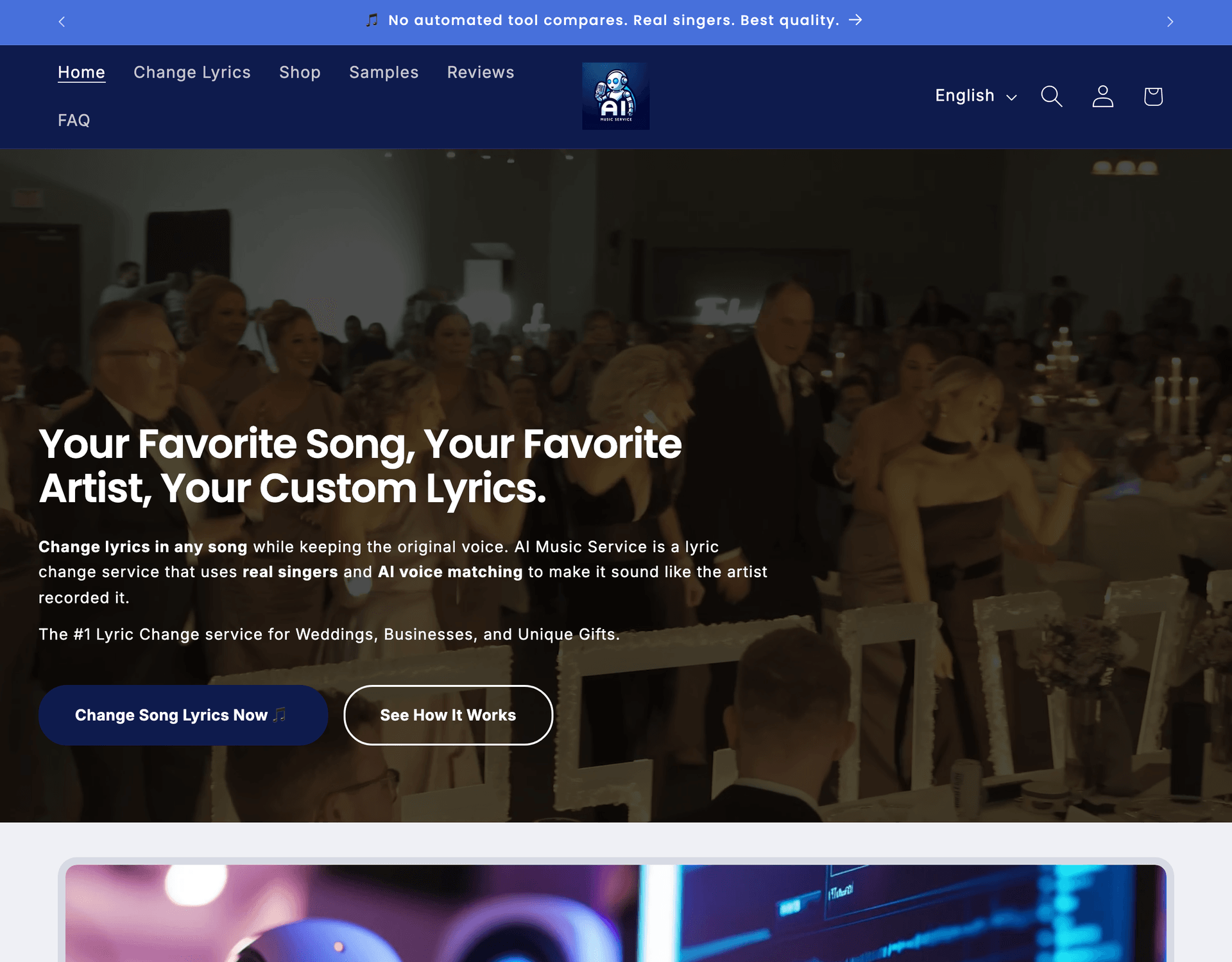
AiMusicService
AI-integrated music services e-commerce platform
How you can hire.
Three ways to engage.
Dedicated Full-Time
A senior developer working exclusively on your product, embedded into your team, sprint cycle, and rituals. Best for roadmap-driven work with continuous shipping.
Part-Time / Fractional
Two to three days a week of senior expertise. Ideal for early-stage teams, technical advisory, code review, or supplementing an existing in-house team.
Fixed-Scope Project
Defined milestones, outcomes, and timeline. Best when the brief is clear and you want a predictable budget. Includes design, QA, and handover.
How it works.
Simple. No theatre.
- 01
Quick intro call
A 30-minute conversation. Tell us what you're building, the stack you're on, and where you'd like help. No deck, no obligation.
- 02
We share our experience
We walk you through relevant projects we have shipped, the approach we would take, and the trade-offs to expect. Honest about what we are great at — and what we are not.
- 03
Start work
Mutual NDA, a clear scope, and a start date. We begin shipping that week. Daily updates and a single point of contact throughout.
What clients say.
On llm developer work.
Verified Upwork reviews from teams we've shipped for.
"Great freelancer — proactive, thinks outside the box, and responds quickly. I hired them for the second time and will definitely hire again for future projects. Thanks!!"
FAQ.
Common questions.
Which model do you recommend?
Depends on the workload. Claude Opus 4.7 for hardest reasoning. Claude Sonnet 4.6 for most production work — best ratio of quality to cost. Claude Haiku 4.5 for high-throughput. GPT-5 family for tool use. We design code to be model-agnostic and benchmark on your actual prompts.
How do you handle prompt caching?
Anthropic prompt caching for repeated system prompts and long contexts. Properly designed, it cuts cost 60–90% on repetitive workloads. We layer it with semantic-cache for similar queries.
Tool use vs MCP?
Tool use for in-context tools that the model controls. MCP for connecting AI to external systems through a standardized protocol. We build both — and increasingly, MCP servers expose data sources to multiple AI products, which is where it shines.
How do you handle hallucinations?
Constrain output: structured generation with JSON schemas, citation requirements, refusal patterns when retrieval confidence is low. Combine with eval harnesses that catch regressions on adversarial cases.
Open-weight models — when?
When data sovereignty, cost-at-volume, or fine-tuning is critical. Llama 3, Mistral, and Qwen are production-ready. We deploy on Modal, Together, or self-hosted GPUs depending on requirements.
Streaming — always or sometimes?
Always for user-facing UX. Token streaming makes LLM features feel fast even when total latency is high. We use the AI SDK's `streamText` / `streamObject` patterns by default.
How fast can a developer start?
For most roles, within 5–10 business days from the intro call. We pre-qualify our bench so onboarding is contracts and access — not a hiring search.
Do you sign NDAs and IP assignment agreements?
Yes — every engagement starts with a mutual NDA and a clean IP assignment clause. All work product is your property the moment it's written.
What time zones do your developers cover?
Our team primarily operates in IST with 4–6 hours of overlap with US Pacific, full overlap with EU, and full overlap with AU East. We commit to overlap windows in writing.
Related roles.
Also worth a look.
Ready to start?
Let's chat.
Tell us what you're building. We will reply within 24 hours, hop on a quick intro call, walk you through relevant work we have shipped, and take it from there.
Prefer email? info@techyor.com
What are you looking for?
Please choose an option below